VIPERSHADOW
Dark Web Investigation Platform
● In Progress · v0.2.01. Snapshot
2. Why I Built This
Existing dark web tooling forces a choice between shallow and unaffordable:
- Free OSINT scanners (Robin, OnionSearch, Ahmia) go one layer deep and return a link dump with no matching, IOC extraction, or real analysis
- Credential monitoring services (Dark Web ID, SpyCloud, Breachsense) only watch for breached emails on a recurring schedule — they don't investigate anything beyond credentials
- Enterprise threat intelligence platforms (Recorded Future, Flashpoint, Intel 471, DarkOwl) do real investigation at depth, but cost $50k–$500k per year and assume a dedicated CTI team
The security operator who needs to actually investigate something — a threat actor during an active incident, a malware family in research, exposed infrastructure during attack surface review, a fresh breach landing on the desk — has nowhere to go between those tiers.
VIPERSHADOW exists to close that gap. Investigation-grade depth, self-hosted, single-operator workflow, no recurring license fee. Built for the operator who needs to answer "what do we actually know about this?" without a $100k Recorded Future seat to point at the question.
3. What It Does
Four Investigation Modes
Identity (Email, Username, Full Name, Phone), Threat Actor (Group Name, Alias, Malware), Domain (Domain, IP), Keyword (Search term). Each mode runs against tuned LLM prompts and target field sets appropriate to the investigation type.
Multi-Layer Tor Scraping
L1–L4 adaptive depth scraping through Tor. L1 follows search results, L2 follows links on L1 pages, L3 follows internal links on matched L2 pages, L4 follows internal links on exact-matched L3 pages. Adaptive — depth increases only when matches keep landing. Where single-layer OSINT tools grab the matched page and stop, VIPERSHADOW follows references two and three layers deep.
Four-Pass Match Engine
Exact string match, rapidfuzz fuzzy-high (>85% confidence), rapidfuzz fuzzy-low (70–85% confidence), and regex pattern matching. Pages under 300 characters and search-result-page titles are discarded before matching.
IOC Extraction
Emails, onion addresses, BTC/ETH/XMR cryptocurrency wallets, IPs, clearnet domains, MD5/SHA1/SHA256 hashes, and CVE identifiers. Runs only on pages with substantive content (500+ characters, non-search URLs).
LLM-Driven Analysis
The LLM analyst receives only matched excerpts and extracted IOCs — never unmatched scrape content. Returns a structured intelligence report with HIGH/MEDIUM/LOW confidence findings across Threat Actor Profile, Attack Methodology, Infrastructure Indicators, Victim Profile, and Current Activity Assessment sections. Generates suggested Next Queries to drive the investigation forward. Returns explicit INSUFFICIENT DATA flags when signal is weak rather than fabricating findings.
4. How It Works
The operator-in-the-loop pipeline:
Standard-depth scans complete in roughly 10–15 minutes. The operator-in-the-loop layer (gated content handling) is the current v0.2.0 milestone. The multi-layer scraping and match/IOC/synthesis pipeline are operational and producing substantively more usable intelligence than shallow OSINT alternatives on the same queries.
5. Screenshots / Artifacts

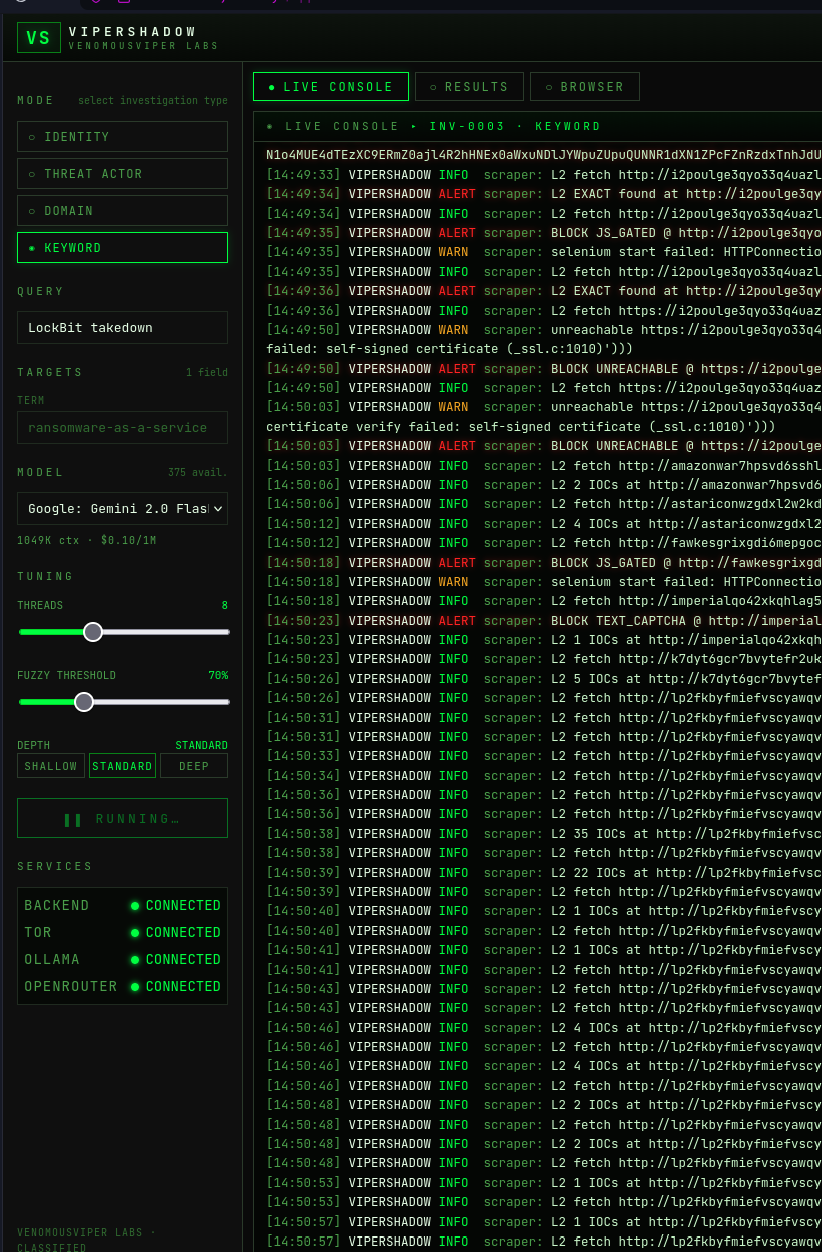

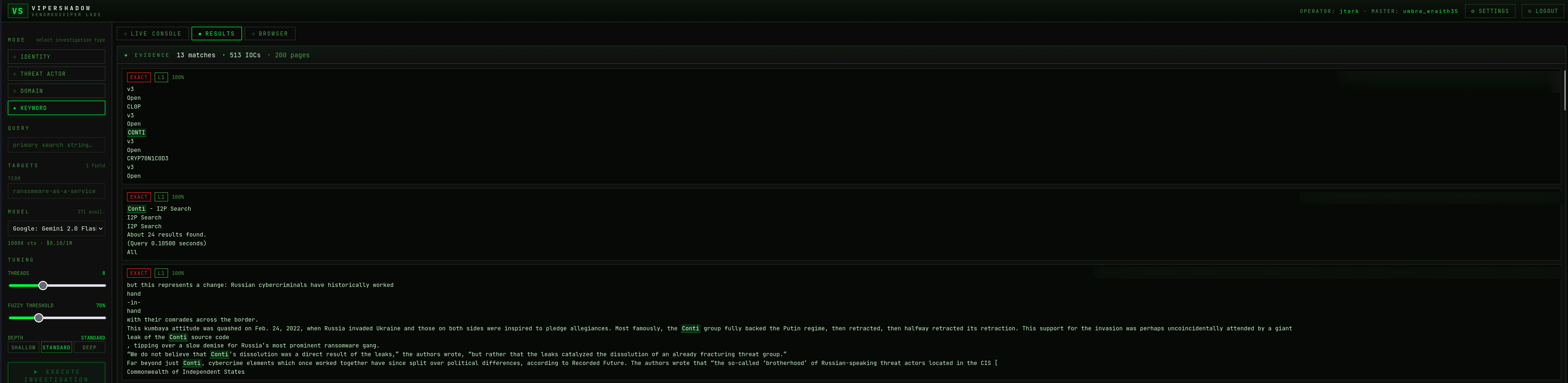
A single Threat Actor investigation against a well-documented historical target produced 13 matches, 513 extracted IOCs, and 200 pages scraped — with the LLM synthesizing five sections of HIGH-confidence findings. Depth comes from multi-layer scraping against open content; gated content handling expands coverage further as the v0.2.0 milestone completes.
6. Links
GitHub Repository Project WikiSource code is currently private while the v0.2.0 milestone is completed. The public README and Wiki document the project's architecture, design decisions, and operational characteristics. Source will be published at v1.0.0.